When building an initial prototype, its only purpose is to exist, to hold space, to help us think through how everything fits together. The worse the performance, the better. It serves as a rock bottom baseline against which we can measure all future improvements.
That means that it isn’t important to think about making the individual pieces work well, but it is important to think about how they fit together and make sure they work together smoothly. It’s more about defining structure and interfaces than anything else.
The process
It wasn’t pretty. Directories got created, renamed, moved, moved back, and deleted. Functions that were in one module got moved to another. Modules got combined and split. The layout of the tests changed three times and I’m still not entirely happy with it. During the process, I realized how little I understood what a well structured package should look like and took a detour to write myself this guide. This is all somewhat normal for creating a new project, but it’s important to note that the project wasn’t born looking this way. It evolved.
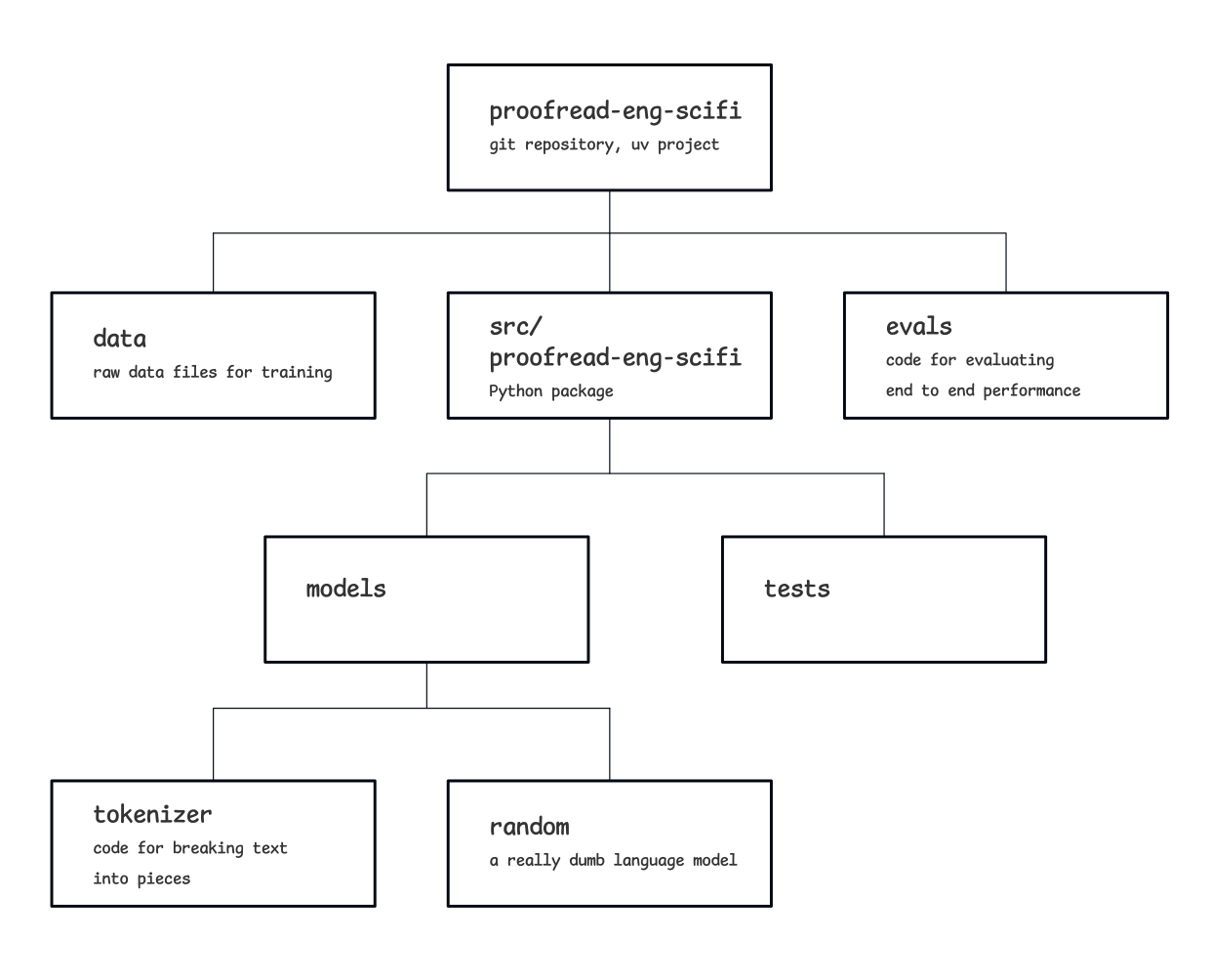
The structure
The resulting project repository is built around
the package code
atsrc/proofread_eng_scifi.
Outside the main package code, there is a data directory with a copy of
the complete training data and an eval directory with the evaluation code.
At the moment, all of the tests are low level unit tests, and are scattered
throughout the package directories to be as close as possible to the modules
they are testing. For a small project like this, it’s not a burden to
include them in the package distribution. Saving the extra step of
navigating through the directory tree to find them is a nice convenience.
The package code itself consist of proofreading modules at the top level
(proof_00.py, proof_01.py) which provide entry points to running
the proofreader, and subdirectories for tests and models. I decided to go
with a clunky, explicitly numbered versioning approach:
filename_01, filename_02, etc. This makes it
straightforward to manage which versions of which components are being used.
This approach would get messy if it were a large codebase but again, since
it’s so small, we can get away with it.
The models directory currently contains the tokenizer model and the
random language model. The tokenizer,
discussed previously,
breaks the text into discrete pieces and numbers them. It also has numbered
versions as well as a short script to train each version.
The random language model provides an extremely rough baseline against which future models can be measured. It randomly "estimates" the probability of each token occurring. These are all nonsense estimates, but they have the right shape to be used in our version 01 proofreader prototype.
Returning to the proofreader modules, version 01 is the one that uses the random language model. It uses a command line interface where the name of the text file to be proofread is supplied, for example
uv run proof_01.py to_be_proofread.txt
Then it returns a list of detected errors together with their character positions in the original text file. This again illustrates the "start with something horrible and make it better later" approach. It’s clearly inadequate from a user interface perspective, but it does give some scaffold from which to hang the rest of the prototype.
The proofreader code itself imports the pre-trained tokenizer, as well as the random language model, reads in the file requested, tokenizes it, and gets a probability assigned to each token. The proofreader then implements an arbitrary cutoff of 0.05, and any token with a probability below this is tagged as an error. It also includes some report metrics like how many errors were detected and how many errors per thousand characters, and all of these are displayed in the console.
With important files included, here's what the current structure looks like:
proofread-eng-scifi ├── LICENSE ├── README.md ├── data │ ├── alices_adventures_in_wonderland.txt │ ├── dorian_gray.txt │ ├── dracula.txt │ ├── frankenstein.txt │ ├── hound_of_baskervilles.txt │ ├── legend_of_sleepy_hollow.txt │ ├── lost_world.txt │ ├── ozma_of_oz.txt │ ├── seven_dials.txt │ ├── time_machine.txt │ ├── twenty_thousand_leagues.txt │ └── war_of_worlds.txt ├── evals │ ├── eval_proofreading.py │ ├── spelling.py │ └── test_evaluation_data.py ├── pyproject.toml ├── src │ └── proofread_eng_scifi │ ├── models │ │ ├── random │ │ │ ├── lm_random_00.py │ │ │ └── test_lm_random_00.py │ │ └── tokenizer │ │ ├── model_versions │ │ │ ├── tokenizer_00.model │ │ │ └── tokenizer_00.vocab │ │ ├── test_tokenizer_training.py │ │ ├── tokenizer_tools.py │ │ └── train_tokenizer_00.py │ ├── proof_00.py │ ├── proof_01.py │ └── tests │ ├── test_proof_00.py │ └── test_proof_01.py └── uv.lock
This will continue to evolve, but here is a link to the commit captured in the directory tree above.
Integration with the evals
This end-to-end prototype now has just enough substance to it to let us run the evals against it. The spelling eval described here can call the proofreader through a function and run each of its five mistake-ridden paragraphs against it. Because the evals have a ground truth key for the actual mistakes, it can compare the detected mistakes and find where the hits and misses were. Any ground truth mistake that was overlapped by at least one detection is considered detected, a true positive. Similarly any ground truth mistake that has no overlaps is considered missed, a false negative. And any detected mistake that doesn’t overlap a ground truth mistake is considered a false positive. These then get combined to calculate precision and recall, the metrics of choice for the evals created.
It’s worth noting that neither precision nor recall is zero. Precision is typically 8-12% and recall is typically 15-25%. The random baseline sometimes gets it right.
Random baseline
For most models, a safe place to start a baseline is a random number generator. Instead of making predictions that are intelligent in any way, just roll the dice each time. This is where we started with our spellchecker. For some tasks and performance metrics this will give near zero, but for others it could be much higher. For example, a random baseline on a true/false quiz would be about 50%. Knowing where the performance floor lies is helpful when it's time to interpret the performance numbers of future models.
Consistency
Consistent style makes code easier to read and helps bugs to be more visible.
I aim to keep my code mostly consistent and mostly in line with
the recommendations of PEP 8,
but if I have good reason to deviate I don't hesitate. For example,
in most places I pust test files in the same directory as the modules they
test, but in src/proofread_eng_scifi I opted to put them in their
own subdirectory. Because of how I foresee the project evolving, this
made the most sense to me.
I've seen some wildly verbose and incomprehensible code that resulted from blindly keeping to consistent convensions. As Ralph Waldo Emerson notes in his seminal essays on coding standards, "A foolish consistency is the hobgoblin of little minds". This roughly translates to "use common sense". In particular, think about who is going to running and reading your code, and try to make their lives as easy as possible. Future you will thank you.
Next steps
Now that there is a skeleton end-to-end prototype in place, the next steps will be to start improving it piece by piece and re-evaluating it after each step. There is plenty of room for improvement. The evals are incomplete, the language model is laughably bad, the tokenizer has options to experiment with, and the UI needs a whole lot of polish.
Things are just starting to get interesting.